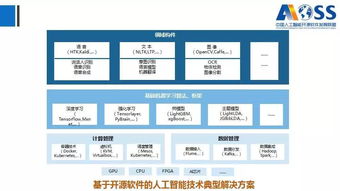
随着人工智能技术的飞速发展,其应用已渗透到社会生活的方方面面,从智能推荐、人脸识别到自动驾驶,AI正在重塑我们的世界。这一进程也伴随着日益严峻的隐私危机。数据是人工智能的“燃料”,但海量个人信息的收集、处理与分析,常常在用户不知情或未充分知情的情况下进行,导致隐私边界模糊、数据滥用风险激增。尤其在人工智能基础软件开发层面,隐私保护问题更为突出,因其直接决定了上层应用的隐私安全基础。
人工智能基础软件开发中的隐私危机主要体现在几个方面。训练数据往往包含大量敏感个人信息,若未经过充分的匿名化或脱敏处理,极易造成隐私泄露。许多基础算法模型本身可能“记忆”训练数据中的隐私信息,即使在部署后仍存在被逆向攻击提取的风险。开源框架和预训练模型的广泛使用,虽然促进了技术民主化,但也可能因代码漏洞或恶意植入导致隐私数据在传输、存储环节被窃取。开发过程中对第三方数据源和工具链的依赖,进一步增加了隐私保护的复杂性。
处理这一危机,需要从技术、法规与伦理多个维度协同推进。在技术层面,隐私增强技术(PETs)成为关键突破口。包括联邦学习,它允许模型在本地数据上进行训练,仅共享模型参数而非原始数据,从源头减少隐私暴露;差分隐私,通过向数据或查询结果添加可控噪声,在保证统计分析有效性的防止个体信息被识别;同态加密,支持对加密数据进行直接计算,实现“数据可用不可见”。基础软件开发中,应将这些技术内嵌为默认或可选的模块,降低应用层的隐私保护门槛。
必须推行“隐私保护设计”和“默认隐私保护”原则。这意味着在基础软件开发的初始阶段,就将隐私保护作为核心需求纳入架构设计,而非事后补救。开发者需要系统地进行隐私影响评估,明确数据生命周期各环节的风险点,并采用最小化数据收集、限时存储、目的限定等策略。
法规与标准是外部刚性约束。全球各地如欧盟的《通用数据保护条例》(GDPR)、中国的《个人信息保护法》等,已为AI数据处理设立了法律框架。基础软件开发需主动遵循这些法规,并积极参与行业标准的制定,如数据格式、接口规范、安全认证等,以实现合规互操作。
培育开发者的隐私伦理意识至关重要。通过教育、培训与行业倡导,使尊重用户隐私成为技术社群的共同价值观和责任。鼓励开源社区建立隐私审查机制,对贡献的代码进行安全与隐私审计。
化解人工智能时代的隐私危机,尤其在基础软件这一基石领域,是一场需要持续投入的攻坚战。它要求技术创新、法律监管与伦理建设三者并举,在享受AI红利与捍卫个人隐私之间,寻找动态且坚实的平衡点,从而推动人工智能向着更安全、可信、负责任的方向发展。